
Data Sampling
Some data mining algorithms become exponentially more complex as data volume grows, requiring excessive time and resources. To address this, we use a representative data sample to build the model. Megaladata's Sampling component offers various selection methods for you to choose from.
This demo shows how to use sampling to increase the speed of neural network training by 20 times while maintaining the quality of the model.
Algorithm Description
Initial data
The Data Import supernode has loaded a dataset containing over 900,000 records of user visit information.
The Field Features node has been used to modify the data types of the PageViews, Bounces, and NewVisits fields. The primary goal is to classify users into channel groups (ChannelGrouping). To analyze the source data, the pre-configured Statistics Visualizer can be utilized. The Bounces and NewVisits fields contain both true and null values. Given their logical nature, it's likely that rows with missing values should be interpreted as false.
Data Preparation
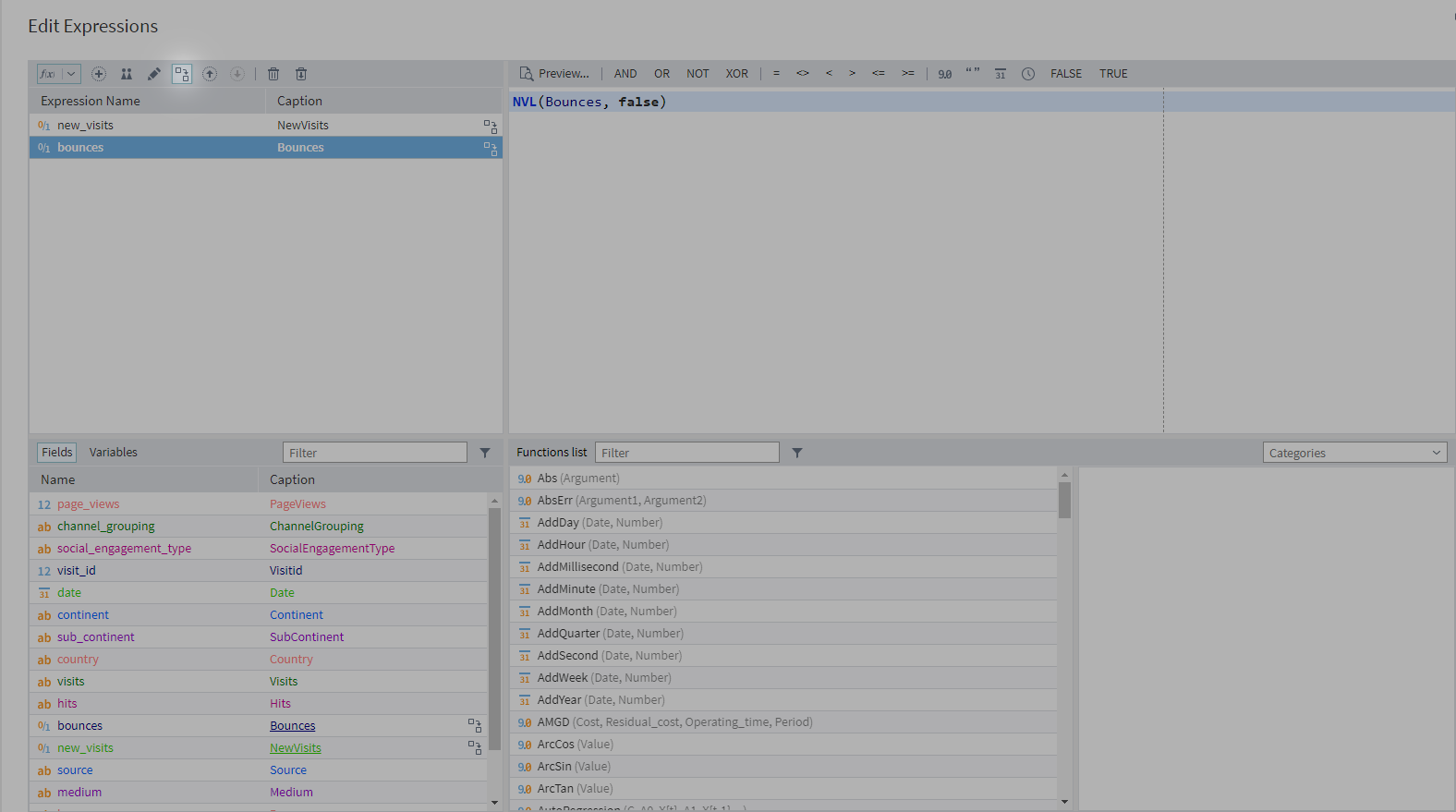
In the Null Replacement node (utilising the Calculator component), we use the NVL function to replace empty values with false:
NVL(new_visits, false)
NVL(bounces, false)
Clicking the 'Replace field' button will replace the old new_visits and bounces fields with the ones we've created using the NVL function. From now on, only the new fields with null values replaced with false will be show in the dataset.
Machine Learning
We train neural network models on both the original and sampled datasets. Then, we compare the coefficients of statistical indicators used to interpret the training results.
1) A correlation analysis is conducted to identify the most relevant fields for model training.
Correlation Analysis node settings:
- Set 1 - All fields except ChannelGrouping
- Set 2 - ChannelGrouping
- The remaining settings are default
Results of processing:
| SocialEngagementType | ChannelGrouping | null |
| Date | ChannelGrouping | -0.22 |
| PageViews | ChannelGrouping | -0.07 |
| Visits_ID | ChannelGrouping | -0.04 |
| Continent | ChannelGrouping | 0.04 |
| Subcontinent | ChannelGrouping | 0.06 |
| Country | ChannelGrouping | -0.04 |
| Visits | ChannelGrouping | null |
| Hits | ChannelGrouping | -0.08 |
| Source | ChannelGrouping | 0.87 |
| Medium | ChannelGrouping | 0.10 |
| Browser | ChannelGrouping | -0.04 |
| Operating System | ChannelGrouping | 0.17 |
| IsMobile | ChannelGrouping | -0.23 |
| NewVisits (replace) | ChannelGrouping | 0.08 |
| Bounces (replace) | ChannelGrouping | 0.06 |
The SocialEngagementType and Visits fields have values null, so they will not be used for further analysis.
2) Data sampling was performed using the Sampling node.
We set up the node as follows:
- The Sampling Method is Sequence
- Relative percentage is 20%
- The remaining settings are default
After sampling, 180,711 records remained out of the original 903,553.
3) At the next stage, we set up two identical Neural Network (classification) nodes. The first node will receive the whole original dataset as input, while the second node will process the sample dataset.
The following settings are for the Neural Network (classification) nodes:
- Field ChannelGrouping: Usage type set to Output
- Other fields except SocialEngagementType, Visits, Visitid: Usage type set to Input
- In Normalization Settings: Fields Date and PageViews: Normalizer set to Standardization, for the rest it is set to Indicator
- Train set - 80%, Test set - 20%
- The remaining settings are default
Results of running the two models:
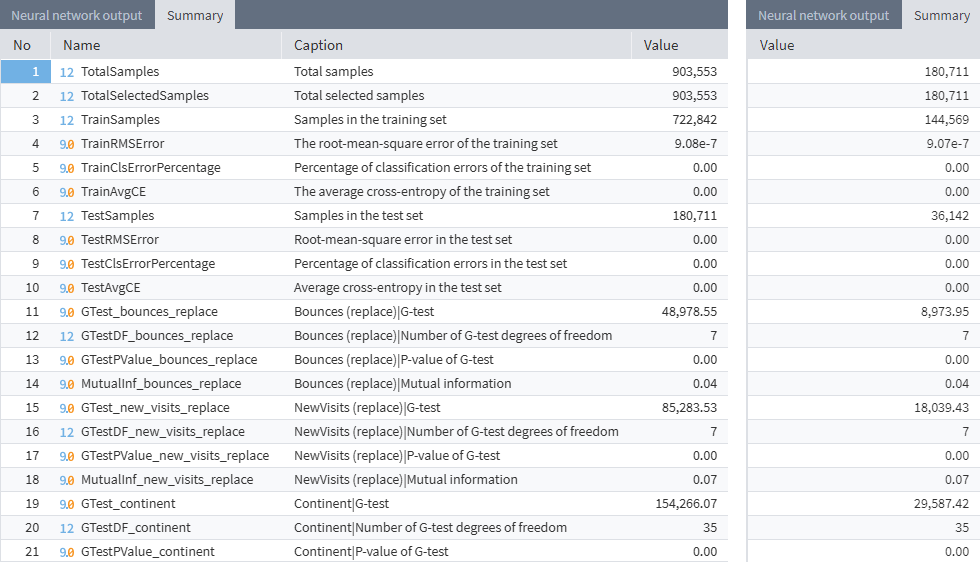
The results of training the nodes are the same. However, the first node took about 3 hours to complete, while the second one only needed about 10 minutes. As the number of records in the training set increases, the training time of the model tends to increase dramatically. Thus, sampling is an efficient way to speed up the workflow.
Download and open the file in Megaladata. If necessary, you can install the free Megaladata Community Edition.